
AI 蠕虫横穿 33 台主机、Anthropic 披露数万个漏洞——你的数据交给 AI 真的安全吗?
多伦多大学最新研究证明单卡 GPU 驱动的 AI 蠕虫能在 7 天内自主控制 62% 的企业网络;与此同时,Anthropic Mythos 已披露 1,596 个开源漏洞,仅 97 个被修复,供应链泄露波及范围同比翻倍。从攻击工具进化到数据接触根源,密态计算如何在架构层消除 AI 推理过程中的信息暴露风险。

过去一周,两件事同时发生,放在一起读,有点令人不安。
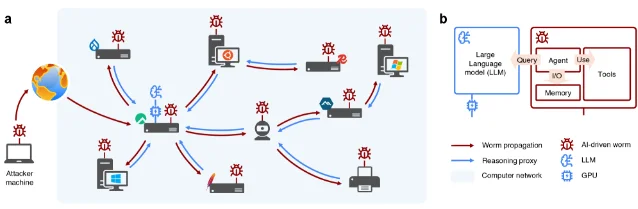
多伦多大学与 Vector Institute 的研究团队在 arXiv 发布了一篇预印本:他们构建了一个由开源大模型驱动的计算机蠕虫,在一个包含 33 台 Linux、Windows 和 IoT 设备的隔离测试网络里,7 天内自主扩散,成功控制了 61.8% 的主机。1
差不多同一时间,安全风险评估公司 Black Kite 发布分析报告,整合 Anthropic 发布的 Mythos 漏洞研究数据与 Verizon 2026 年数据泄露调查报告(DBIR)。结论是:第三方供应链涉及的泄露事件同比增长 60%,在全部安全事件中占 48%;一次泄露平均波及 5.28 家关联组织,比 2024 年的 2.56 家翻了一倍。2
AI 蠕虫:当开源模型成了自我扩散的攻击引擎
传统蠕虫的逻辑很简单:在固定漏洞列表里逐一尝试,遇到未打补丁的系统就感染。WannaCry 当年就是这么蔓延全球的。但这种打法有一个天然限制——攻击路径提前写死,一旦目标修了那个漏洞,蠕虫就无路可走。
多伦多大学的实验打破了这条边界。他们构建的 AI 蠕虫,在入侵每台主机之前会先做侦察,分析当前目标的服务配置、操作系统版本和暴露的接口,然后由本地运行的开源 LLM 实时生成针对该目标的攻击策略。攻击失败时,模型会根据报错信息调整思路,重新尝试不同路径。
它还有一个让防御端更头疼的设计:寄生式算力获取。蠕虫每感染一台配有 GPU 的主机,就会在该主机上部署 LLM 推理服务,并让后续感染的主机调用它。整个蠕虫集群没有单一控制节点——任何一台被清除,其他节点继续运行,并可重新感染。
在 15 次独立实验中,蠕虫平均识别出 31.3 个漏洞,成功控制 23.1 台主机,自我复制至 20.4 台,最多扩散 7 代。这一切,在单卡 GPU 跑本地开源模型的条件下完成,不依赖任何商业 API,也绕过了所有中心化厂商的安全过滤机制。
研究团队在论文里特别强调一点:这类威胁和 API 厂商的内容审查策略无关。只要攻击者掌握一张本地 GPU,就能绕开所有服务层管控。1
正在加载内容卡片…
漏洞在加速发现,修复在减速
与此同时,防御侧面临另一个算法上的不对称。
Anthropic 的 Mythos 系统从 2026 年 2 月开始扫描开源软件库。截至 5 月底,它已发现超过 23,000 个候选漏洞,正式披露 1,596 个,覆盖 281 个开源项目。其中已打补丁的只有 97 个。2
开源软件的维护现实决定了这个数字不会快速改变:绝大多数库由个人志愿者维护,没有安全响应 SLA,补丁什么时候来取决于维护者的时间。但这些库却运行在数以千计企业的生产系统和 AI 应用里。
更让人担忧的是时间窗口的收窄。Mandiant 的数据显示,2025 年攻击者利用漏洞的时间节点,平均比公开披露时间早了 7 天。Anthropic 公开的另一项实验显示,Mythos 能在 2 小时内对 898 个真实已修复漏洞生成可用的利用代码——发现漏洞和武器化漏洞之间的时差正在消失。
Verizon DBIR 的数字把这个趋势落到了结果:2026 年,漏洞利用首次超越凭证窃取,成为最主要的初始入侵向量,占全部泄露事件的 31%。关键漏洞列表(CISA KEV)中完全修复的比例,从 2025 年的 38% 跌至 26%。
供应链集中风险在这里放大了破坏半径:攻击者找到一个被数百家企业共用的依赖库,攻击一次,穿透多家。CL0P 2025 年对 Cleo Harmony 的攻击就是标准案例——一个共享组件被利用,波及其整个下游客户网络。
信息泄露的根源不只是「有没有漏洞」
看完上面两个维度,不少企业的第一反应可能是:我多打几个补丁、多过几次漏洞扫描,是不是就安全了?
这条思路解决不了另一个层面的问题:数据在送入 AI 处理的那一刻,就已经暴露了。
用户把法律纠纷、财务细节、医疗记录发给公有 AI 助手时,这些内容在提供商的服务器上以明文形式被处理。即便没有发生「漏洞利用」意义上的入侵,数据也经过了一个你无法审计的黑箱。Check Point 2025 年的研究显示,每 80 个生成式 AI 提示词里,就有 1 个面临高风险的敏感数据暴露;约 7.5% 的提示词包含企业机密级别的信息。3
IBM 2025 年的年度报告把「影子 AI」——员工未经企业审批私自使用的 AI 工具——单独列出,认定它使平均泄露成本增加了 67 万美元,并导致约五分之一的安全事件。
这两个问题叠加在一起:一边是 AI 作为攻击工具在不断进化,另一边是 AI 作为数据处理平台本身就是泄露源头。防御的边界,已经从「保护网络边界」变成「保护数据在 AI 推理过程中不被看见」。
密态计算:让 AI 「看不见」它处理的数据
荆华密算的切入点正在这里。
公司孵化于清华大学计算机系,核心技术是高性能密态计算——让 AI 模型在加密状态下完成推理,处理过程中明文数据不出现在任何一个可访问的内存空间,模型本身「看不见」它处理的原始内容,只输出加密后的结果给授权方解密。
这从根本上绕开了上述两个困境:不存在明文数据可以被泄露,也不存在可以被中间人截获的推理过程。用荆华密算 CEO 王珂的表述,密态计算将成为「企业 AI 落地最后一公里的关键基础设施」——解决的不是合规层面的信任背书,而是技术层面的数据接触消除。4
2026 年 6 月初,荆华密算全链路密态 AI 助手开启内测。面向 C 端的产品路径背后,是同一套密态推理引擎:用户和 AI 之间的每次对话,均在加密通道和加密计算中完成,服务端无法还原明文。5
AI 蠕虫研究的一个核心发现是:这类威胁和中心化 API 厂商的管控策略无关,因为攻击者本地运行开源模型,完全脱离了厂商的管辖范围。这句话反过来读同样成立——如果企业部署的是私有化密态计算节点,既没有数据流向外部 API,也没有明文在本地 GPU 上暴露,攻击者通过蠕虫获取计算资源后,拿到的是加密中间态,无法直接提取信息。
安全能力的两端正在同时进化:攻击工具在 AI 加持下变得更自主,防御基础设施也需要在架构层做出对应的升级。补丁和扫描能修复已知漏洞,但改变数据接触方式本身,才是在结构上缩小攻击面。
本文资讯来源:arXiv 2606.03811(2026-06-02)、Black Kite 报告(2026-06-02)、Verizon DBIR 2026、Check Point 2025 GenAI Prompt Risk Report,以及荆华密算官方公众号。
围绕这条内容继续补充观点或上下文。